Azure Databricks Features and Implementation Architecture
What
is Databricks?
-
Databricks
provide
Unified Analytics Platform that accelerates innovation by unifying
data science, engineering and business. Databricks advantage is it
is that is easier to use, it has native Azure AD integration and
also has performance improvements over traditional Apache Spark.
-
Founded
by the team that created Spark. Most of the open source committers
and PMC members of Spark are from Databricks.
-
People
at Databricks contribute to Spark and focus on making Apache Spark
the most used Big Data Engine. Trying to enhance Spark to make it
better day by day.
Why
Databricks?
-
Databricks
makes it very easy to create a Spark cluster out of the box vice
determining the requirements for a particular use case.
-
Databricks
allows multiple users to run commands on the same cluster and
running multiple versions of Spark. Because Databricks is also the
team that initially built Spark, the service is very up to date and
tightly integrated with the newest Spark features.
-
Instead
of one data scientist writing AI code and being the only person who
understands it, everybody uses Azure Databricks to share code and
develop together .
-
It
enables customers to scale globally without limits by working on big
data with a fully managed, cloud-native service that automatically
scales to meet their needs, without high cost or complexity.
Delta
Lake-
Delta
Lake is an open-source storage layer that brings ACID
transactions
to Apache Spark and big data workloads.
Delta Lake is open source through which developers will be able to
easily build reliable data lakes and turn them into Delta Lakes.
Features
in Delta Lake--
-
The
foremost feature of delta lake is that it
brings ACID
transactions
to your data lakes. It provides serializability, the strongest level
of isolation level.
-
Its
scalabale metadata
handling
treats metadata just like data, leveraging Spark's distributed
processing power to handle all its metadata. As a result, Delta Lake
can handle petabyte-scale tables with billions of partitions and
files at ease.
-
Its
schema evolution
enables you to make changes to a table schema that can be applied
automatically, without the need for cumbersome DDL.
-
Developers
can use Delta Lake with their existing data pipelines with minimal
change as it is fully compatible
with Spark.
-
All
data in Delta Lake is stored in Apache Parquet format enabling Delta
Lake to leverage the efficient compression and encoding schemes that
are native to Parquet.
-
A
table in Delta Lake is both a batch table, as well as a streaming
source and sink. Streaming data ingest, batch historic backfill, and
interactive queries all just work out of the box.
-
Delta
Lake provides snapshots of data enabling developers to access and
revert to earlier versions of data for audits, rollbacks or to
reproduce experiments.
Databricks
provide
Unified Analytics Platform that accelerates innovation by unifying
data science, engineering and business. Databricks advantage is it
is that is easier to use, it has native Azure AD integration and
also has performance improvements over traditional Apache Spark.
Founded
by the team that created Spark. Most of the open source committers
and PMC members of Spark are from Databricks.
People
at Databricks contribute to Spark and focus on making Apache Spark
the most used Big Data Engine. Trying to enhance Spark to make it
better day by day.
Databricks
makes it very easy to create a Spark cluster out of the box vice
determining the requirements for a particular use case.
Databricks
allows multiple users to run commands on the same cluster and
running multiple versions of Spark. Because Databricks is also the
team that initially built Spark, the service is very up to date and
tightly integrated with the newest Spark features.
Instead
of one data scientist writing AI code and being the only person who
understands it, everybody uses Azure Databricks to share code and
develop together .
It
enables customers to scale globally without limits by working on big
data with a fully managed, cloud-native service that automatically
scales to meet their needs, without high cost or complexity.
The
foremost feature of delta lake is that it
brings ACID
transactions
to your data lakes. It provides serializability, the strongest level
of isolation level.
Its
scalabale metadata
handling
treats metadata just like data, leveraging Spark's distributed
processing power to handle all its metadata. As a result, Delta Lake
can handle petabyte-scale tables with billions of partitions and
files at ease.
Its
schema evolution
enables you to make changes to a table schema that can be applied
automatically, without the need for cumbersome DDL.
Developers
can use Delta Lake with their existing data pipelines with minimal
change as it is fully compatible
with Spark.
All
data in Delta Lake is stored in Apache Parquet format enabling Delta
Lake to leverage the efficient compression and encoding schemes that
are native to Parquet.
A
table in Delta Lake is both a batch table, as well as a streaming
source and sink. Streaming data ingest, batch historic backfill, and
interactive queries all just work out of the box.
Delta
Lake provides snapshots of data enabling developers to access and
revert to earlier versions of data for audits, rollbacks or to
reproduce experiments.

Azure Databricks
Azure
Databricks is designed in collaboration with Databricks whose
founders started the Spark research project at UC Berkeley, which
later became Apache Spark.Designed
with the founders of Apache Spark, Databricks is integrated with
Azure to provide one-click setup, streamlined workflows, and an
interactive workspace that enables collaboration between data
scientists, data engineers, and business analysts.
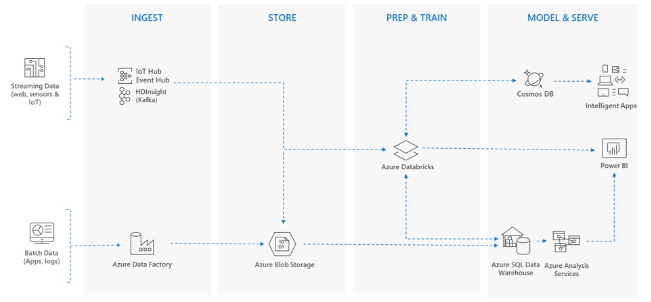
Architecture
to be followed to implement Azure-Databricks in Big data System-

Key
Features in Azure Databricks-
- Azure Databricks’ interactive notebooks enable data science teams to collaborate using popular languages such as R, Python, Scala, and SQL and create powerful machine learning models by working on all their data, not just a sample data set.
- Native integration with Azure services further simplifies the creation of end-to-end solutions. These capabilities have enabled companies such as renewables.AI to boost the productivity of their data science teams by over 50 percent.
- Azure Databricks not only provides an optimized Spark platform, which is much faster than vanilla Spark, but it also simplifies the process of building batch and streaming data pipelines and deploying machine learning models at scale.
- Azure Databricks protects customer data with enterprise-grade SLAs, simplified security and identity, and role-based access controls with Azure Active Directory integration. As a result, organizations can safeguard their data without compromising productivity of their users.
- Integration with Azure Blob Storage, Azure Data Lake Store,Azure SQL Data Warehouse, and Azure Cosmos DB allows organizations to use Azure Databricks to clean, join, and aggregate data no matter where it sits
{kind=link}
👍
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteGreat idea. Integration with Azure will save lot of time required for configuration setup.
ReplyDeleteYes Swapnil and also it will save cost if we use Databricks...
DeleteAwesome👍
ReplyDelete